The Remote Uptime (RU)
Project
History
I started using Unix systems
in approximately 1984 at Colorado State University. At
that
time, Unix was BSD or SysV. TCP/IP was new as was networking
computers in general. Needless to say, I found Unix to be really
cool. Just to date myself, in 1984, the Big Computer on
Campus was a CDC Cyber, and the primary computer that ran the Computer
Science Departement was a Digital VAX 11/750 (not even a 780!).
The computing facilities were HP 9000/300 series workstations/servers
with a blazing 16Mhz
68020 CPU and 8 megabytes of memory and HP/IB storage. Needless
to say, these weren't powerful machines.
When assignments were due, the systems got horribly
busy. The computing system assigned to a paticular class (if only
one) got so slow that it literally was seconds between typing a
keystroke and
seeing it on the screen. Due to this, the idea of using an idle
system from another class became attractive. I would find a
non-busy system, do my editing there, and rcp/rlogin to the primary
host, do my compiles and go back to editing.
As part of this, I found the 'ruptime'
command. It was very handy for figuring out what systems were on
the network and how busy those systems were.
After I left college, I eventually became a Systems
Administrator (SysAdmin). I liked the 'ruptime' functionality for
watching the systems in my environment. However, as soon as I
turned on the ruptime function, I found that the program had a few
major flaws:
- The 'rwhod' daemon that collected the information used
broadcasts, which meant that it didn't work across subnets.
- Each
client must run rwhod to show up in the 'ruptime' list. This
means that every so often (5 seconds?) each client sent a broadcast
declaring it's current status. This caused a HUGE number of
broadcasts for any network larger than 10-15 clients.
- rwhod stores the information for each client locally. That
means
that each client has its own list of rwho status. This
represented
a large amount of wasted storage, as I was the only one looking at the
data, and I was looking from a single workstation.
- maintaining the rwho daemon and storage was a time-waster.
It took time to keep it going.
Due to the problems above, I ended up turning off
rwhod on all of the clients. However, I still wanted
something similar so that I could quickly see system status.
RU is Born
Around this time, I asked a co-worker
of mine, Dave Farnham, whether he had a way to implement
something
similar to ruptime, but without the nasty edges. Dave spent a
weekend (he's a wiz) and came up with an RPC based system that operated
in a client-server mode. By using RPC, the solution was very
portable, and easily ported to pretty much everywhere. The
initial version reported only system uptime by using a RPC call from
the client to a centralized server that ran a collection daemon written
in Perl. This initial version appeared in the 1994-1995 timeframe.
Over the next year or two, Dave added history
reporting, system load graphing, and availability reporting.
Around this time, Dave decided to leave the company, and went on to
another
position at another company.
I then took over the maintenance of the ru
source. Over time, I've added a number of features until I
consider it to be a mature, easy to use system status reporting
program.
I find it very handy to simply type 'ru'
periodically to see what is going on in the environment. ru is
very useful for detecting 'just not right' server problems, such as
runaway jobs, high loads, etc.
What is RU?
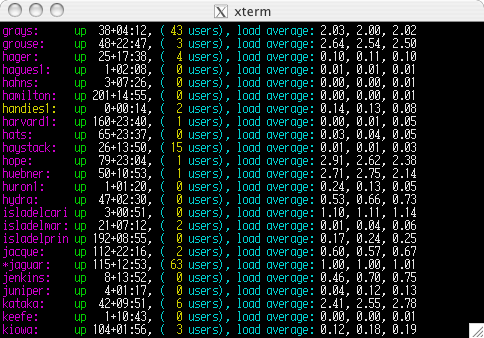
In the above picture the program 'ru' has been
executed against a larger environment of servers. Immediately,
you can see the system name, the system uptime, the load average, and
the number of logged in users. In addition, the coloring of the
text shows a number of additional items. The server 'handies1'
has been booted only 14 minutes ago. It is shown in yellow to
attract attention that the server has booted in the last 24
hours.
Server 'jaguar' has a * in front of it, which
indicates that the system hasn't reported in two minutes. This
actually indicates that the clock on jaguar is out of sync with the
master server, and that the system in question is really more than two
minutes different than the host system. If you deploy ru, you
need to synronize your system clocks with NTP (or something
similar). It's a good idea to synchronize your clocks for
security purposes anyway.
Below represents many (but not all) of the features
of the ru system:
- Clients run a daemon called 'rucd' (ru client daemon). This
client sends a single RPC packet to the central server 'ruserver' once
per minute reporting:
- System Uptime
- Number of users of the system
- Load average of the system
- On Linux only, system paging and cpu %
used
- The
central server 'ruserver' runs 3 daemons:
- rusd
- collects the client reports
- ruds
- processes client requests for information
- rucd
- ru client daemon (for the server to report its own status)
- The
central sever runs a nightly cron job to clean up the daily infomation
and to build the availability reports.
- On
the central system, a program called 'avail' can be run to document
system availability.
- A
perl program 'ru' can be run from anywhere with network reachability to
the server to report on the data collected by ru.
- The
system runs itself. It needs no interaction, and cleans up after
itself.
- The
system will use gnuplot (if installed) to plot system(s) load average
over a 24 hour period. This is handy for comparing loading information
over time. This works by default if run on a Linux system with
gnuplot.
- The
system has groups to allow segmentation of the clients into:
(implict segementation in italic)
- Operating system
- Architecture
- Arbitrary
group (firewall, production, lab, etc.)
- The
system runs on every Unix I've found with minimal changes.
The following are known to work:
- HP-UX
10 and 11
- Linux
- SunOS
and Solaris
- Irix
- OS
X
- Linux
on S390
Installation
Detailed instructions are found in the download
tarball. However, the below represents a simple overview of the
installation:
- Install the server daemons and create the data directories.
- Add startup scripts to the server.
- Start the services.
- Add a dns alias to your server of 'ruserver'.
- Add a single line to the inittab of each client to start the rucd
on boot.
- Start the client via a 'init q'.
Note that the current solution is focused towards a
particular production environment. It should be easily possible
to redefine flags any way desired with the use of a text editor.
If you should have questions, see the forums, or
contact me at shaw at fmsoft
dot com.
Futures
I'd
like to change a few things about how ru works to make it truly
no-brainer install-and-manage:
- Change the server configuration to look up the client group
automatically so that changing the client group can be centralized.
- Switch from RPC to a dedicated socket via Perl (major rewrite).
Thanks to SourceForge.net for hosting this
project.
